We aim to train well-regularized policies that maintain task performance and produces smooth behavior even in highly dynamic tasks.
Problem
- RL policies often exhibit high-frequency oscillations, which is problematic for real-world hardware deployment.
- Can cause actuator damage.
- Not energy efficient.
- Generally undesirable behavior and movement patterns.
This is commonly mitigated by adding penalizations terms to the reward function, minimizing torques, joint velocities, or first (or higher) order action differentials across timesteps.
- Reward design is challenging enough. Fiddling with the reward function can result in performance degradation or behavior that deviates from the original task.
In this work, we look into ways of producing smooth behavior without modifying the reward function at all. We researched the literature and categorized exisiting methods into two types:
1 - Loss-Based Regularization: Methods that adds new constraints on top of the RL loss.

- 2 - Architectural-Based Regularization: Methods that require modifying the structure/architecture of the network in some way.

The shared common principle is to encourage the learning of smooth mappings from input states to output actions, with the assumption that similar or neighboring states must produce similar actions.
3 - Hybrid Regularization: We fused elements from both categories, and investigate a novel Hybrid approach.
- LipsNet + CAPS;
- LipsNet + L2C2.
A total of 8 different methods were investigated (no regularization + 7 regularization approaches).

Benchmark
- 4 staple Gymnasium environments: Pendulum, Reacher, Lunar, and Ant.
- And 4 Robotics tasks (Isaac Gym): ShadowHand, Motion Imitation, Velocity Control, and Handstand.
- Reproducibility and Confidence Intervals: For each task (8), each method (8) is trained from scratch with 9 different seeds.

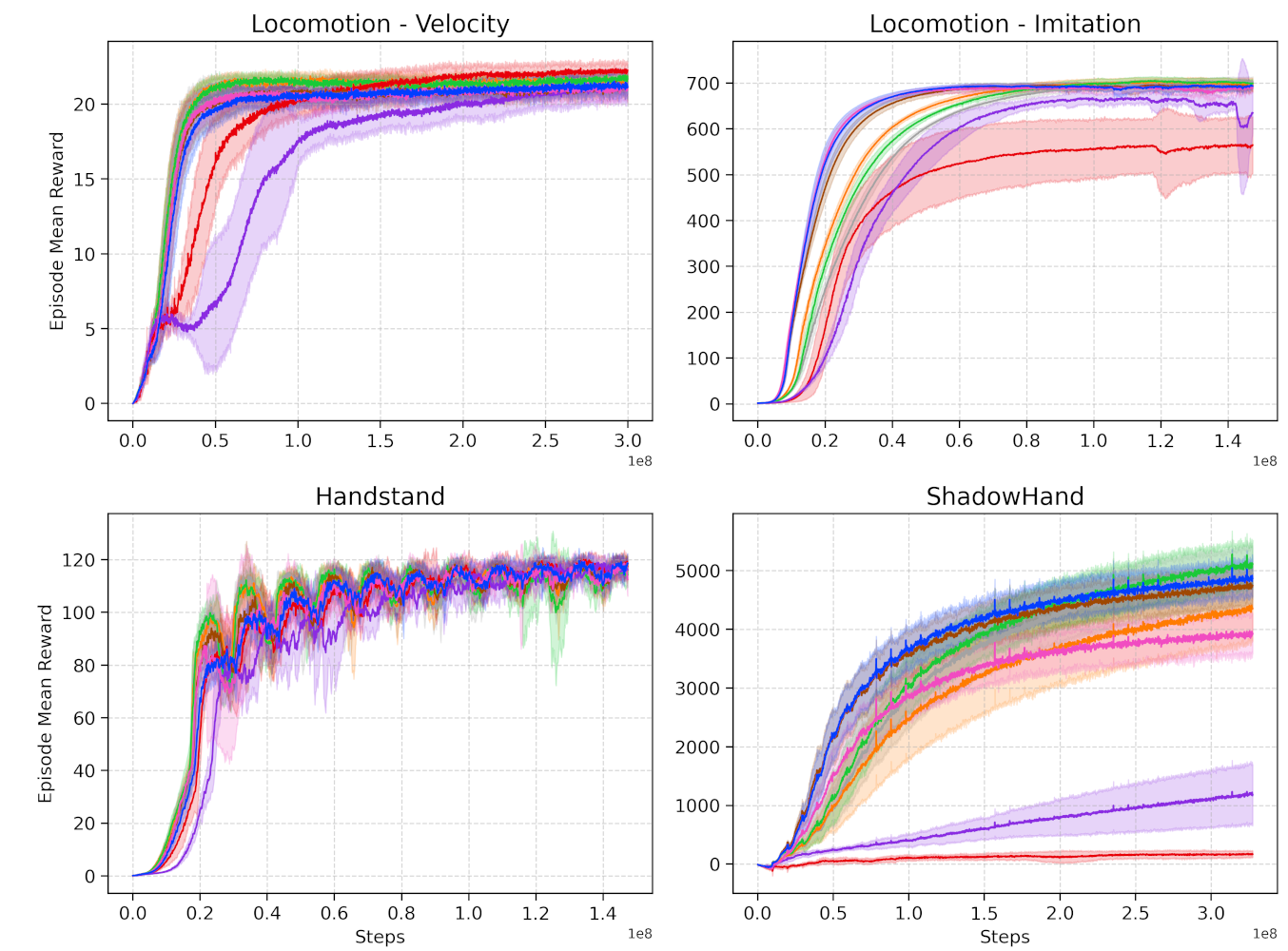

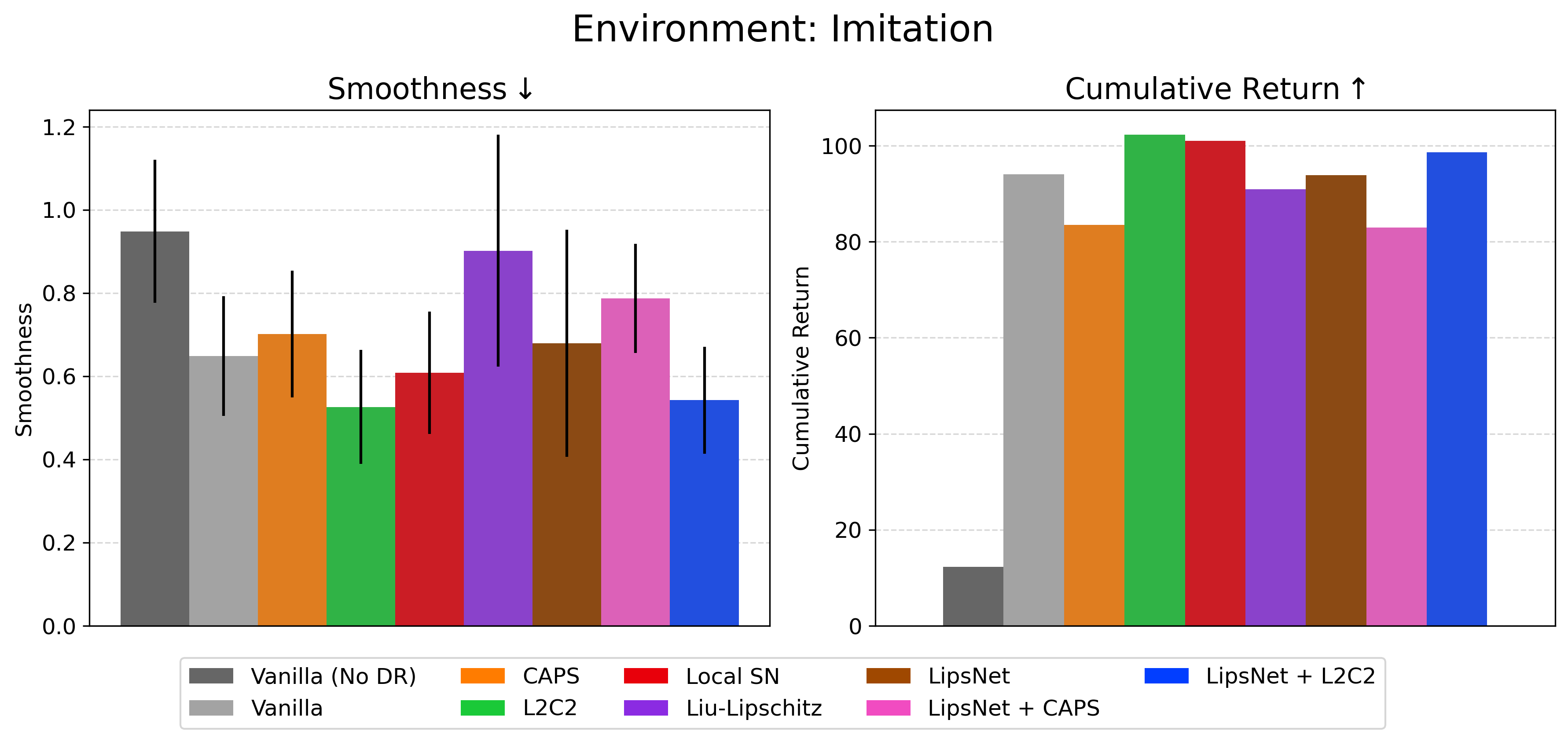
- Results are consolidated in the table below. It displays the average returns and smoothness across all seeds ± 1 standard deviation.

Regularization implies a smothness x performance tradeoff.
Methods such as Local-SN can produce good smothness scores in some tasks, but sacrifice performance or even result in total collapse of the policy.
In most scenarios, our proposed Hybrids outperformed others in terms of smoothness and still maintained high task performance.
- Best Hybrid method reduced control oscillations by 26.8% across all tasks on average.
- Worst-case performance drop of just 2.8% compared to the unregularized baseline.
Real-World
- For the tasks with a quadruped robot, we perform zero-shot sim2real deployment.


Top and bottom stripes display regularized and non-regularized policies, respectively. Smoothness regularization produces emergent behavior where the policy stops movements until the robot is set back to the ground, and is less prone to big jerky movements. The reward function is the same in non-regularized and regularized policies.
General Recommendations for Sim2Real RL Practitioners
- We demonstrate that the hybrid approaches worked the best among all tested methods. However, it's important to note that the architectural approaches, especially LipsNet, come with a training time cost.
- In terms of pure sample complexity, they remain efficient. However, the network's update during the backward pass is slower since these methods rely on computing certain network properties.
- As such, our general recommendation would be to start with a pure loss regularization method such as L2C2. Implementation is straightforward and results can be impactful for many tasks. When/if extra smoothness is required, we recommend proceeding with one of our Hybrid approaches, and facing the increased training time.
References
[7] - S. Mysore, et al., Regularizing action policies for smooth control with reinforcement learning, ICRA 2021
[10] - H.-T. D. Liu, et al., Learning smooth neural functions via lipschitz regularization, SIGGRAPH 2022
[11] - T. Kobayashi, L2C2: Locally lipschitz continuous constraint towards stable and smooth reinforcement learning, IROS 2022
[12] - X. Song, et al., Lipsnet: a smooth and robust neural network with adaptive lipschitz constant for high accuracy optimal control, ICML 2023
[22] - R. Takase, et al., Stability-certified reinforcement learning control via spectral normalization, Machine Learning with Applications, 2022
Cite
@inproceedings{christmann2024benchmarking,
title={Benchmarking Smoothness and Reducing High-Frequency Oscillations in Continuous Control Policies},
author={Christmann, Guilherme and Luo, Ying-Sheng and Mandala, Hanjaya and Chen, Wei-Chao},
booktitle={2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
pages={627--634},
year={2024},
organization={IEEE}
}